IEEE Transactions on Consumer
Electronics
Volume 44, Issue 2, May 1998; pages:388 - 397
VIDEO MIRRORING AND ICONIC GESTURES:
ENHANCING BASIC VIDEOPHONES TO PROVIDE
VISUAL COACHING AND VISUAL CONTROL
Lynn Conway1 and Charles J. Cohen2
1Department of EECS, University of Michigan
2Cybernet Systems, Ann Arbor, Michigan
Abstract
In this paper we present concepts and architectures for mirroring and gesturing into remote sites when video conferencing. Mirroring enables those at one site to visually coach those at a second site by pointing at locally referenceable objects in the scene reflected back to the second site. Thus mirror-ing provides a way to train people at remote sites in practical tasks such as operating equip-ment and assembling or fixing things. We also discuss how video mirroring can be extended to enable visual control of remote mechan-isms, even when using basic videophones, by using a visual interpreter at the remote site to process transmitted visual cues and derive intended control actions in the remote scene.
Keywords:
videophone, video conference, teleconference, video
mirror, visual interpreter, visual coaching, iconic gestures,
gestural control, distance education, human-computer interaction
(HCI), every-citizen interfaces (ECI).
Introduction
The increasing availability of high bandwidth communications, the innovation and standardization of methods for video compression and the VLSI implementation of many functions have brought us to a threshold where video conferencing could soon become a widespread consumer-level technology.
Even now, many companies make PC-based teleconferencing systems, while others make even simpler, stand-alone "videophone" systems. Much effort is being expended to evolve the basic functions and the user interfaces of these systems.
Videophones must be kept simple to hold costs down and to assure ease of use. However, if they are to be widely adopted, they must have functions which add value and make them essential tools in the hands of consumers.
In this paper we first examine the basic functions of current systems. We suggest directions which improvements in low-end systems are likely to take, based on past high-end system experience. We then discuss some functions which can't be done with current video conferencing systems, but which consumers might really like to do.
For example, a user may want to ask someone: "What book is that on your shelf?", while actually pointing at a specific book in the remote scene. This can't be done with current systems. Such questions lead to the concepts of video mirroring and visual control.
As we'll see, video mirroring
can be added at modest cost to a videophone system. Visual control
builds upon mirroring, and enables users to teleoperate remote
mechanisms via an easy-to-use, low-cost user interface. These
functions open up useful new applications, even for rather basic
videophones.
Current Systems
Today's paradigm for the
use of video conferencing is face-to-face conversations and meetings
between remote sites. Users see the others in a window of their
PC screen, or on the monitor of the videophone. Local and remote
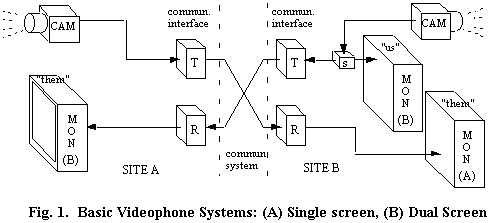
users talk and interact as if looking through a "small glass
window" at each other (see Fig. 1, site
A).
One problem with single-screen (or single-window) systems is that users can't see what they're sending. Since users are blind to the image they are transmitting, they must rely on cues from remote sites to correctly position themselves in their own scene.
Of course, the use of two windows or monitors lets a user see both the incoming and the outgoing scenes (see Fig. 1, site B). Most high-end teleconference systems use such dual-screen setups. This function can be added to single-monitor systems by providing a switch to shift between local and remote scenes, or by employing a split screen or a picture-in-picture (PIP) function.
In any event, users who see "both ends" of the video conference can focus not only on what remote users are showing them, but also on what they are simultaneously showing to remote users. Interactivity is thus enhanced by fuller, more certain communication.
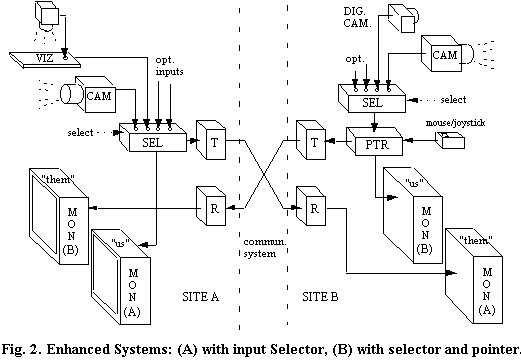
Higher end teleconference systems often add a "copy-stand camera" or video visualizer (VIZ) which users can exploit in addition to the regular camera. Visualizers make it easy to show details of documents or objects to the other site (recall VIZ's being used during the O.J. trial to show artifacts in court).
By including optional video input ports and an input selector (SEL), even basic videophones could allow users to exploit alternative video sources such as visualizers, digital cameras, video output from computers, etc., as shown in sites A and B of Figure 2.
A system which has dual-scene and selectable-input functions can support many interactive scenarios. Each user can look at and show information selectable from many sources. Both users can follow both ends of the interaction. In the future, even basic video-phones could provide such functions, which are now available only on higher-end systems.
Note that the user interface
and system design concepts in this paper are independent of whether
the systems are analog or digital, or whether the communication
links are analog or digital, time or frequency division multi-plexed,
switched, packetized or broadband. All that is required is that
the interfaces and links provide synchronous or isochronous two-way
video (and audio) of sufficient bandwidth for appropriate image
quality and frame rate, and of low-enough end-to-end delay to
support the user application.
What's Missing?
Now let's ask: What's missing? When we interact with computers, we often use a mouse to control a cursor (pointer) to select and edit items on the screen. Such user interactions with displayed information has long been the focus of the field of human-computer interaction (HCI) [1].
However, when video conferencing, we don't generally use a pointer, or make gestures, or even make many explicit references to screen-displayed information; curiously, it just isn't part of the "teleconferencing paradigm".
Of course, there is no essential requirement to "select and edit things" in scenes when video conferencing. But being able to point at and reference objects in real scenes can be useful.
Humans continually interpret complex pointing and gesturing activity during normal face-to-face visual/verbal interactions, which suggests that video conferencing systems could benefit from a pointing capability. (Consider how useful "telestrators" have become for pointing out details of actions during replays of sportscasts).
The pointer's gesturing function is added to a videophone by inserting a basic video pointer subsystem (PTR) between the video camera (or other selected video source) and the local monitor (Fig. 2, site B). The pointer is implemented as a character generator and video overlay mixer in an analog video system. In a digital video system, it is implemented as a cursor generator/image buffer-memory overlay subsystem, operating on the decompressed video stream.
In either case, a joystick, mouse or touch pad is used to move the pointer icon around, and make gestures with it, within the video image. The incremental cost of providing a pointing function can likely be made quite small in future mass-marketed products: the ongoing video-computer-communications convergence is stimulating very low cost VLSI implement-ations of the required subsystems.
Now let's ask again: What's missing? The videophone architecture of site B in Figure 2 lets the site B user point at anything within video originating their site, and that video with the pointer in it will be seen at both sites.
But what if the user at
site B sees something in video coming from site A, and wants to
point out and ask questions about it to the users back at site
A? There is no way to conduct such an interaction using the system
in site B of Fig. 2.
Video Mirroring
Video mirroring was developed
to provide a way for users at a local site to point at items in
video coming from a remote site, such that the users back at the
remote site can see and interpret what's being pointed at [2].
We create the "mirror" by providing a means to retransmit the incoming remote video back to the original site. At first, the idea of returning video to a remote site doesn't seem to make sense (they already "have it"!), and this may explain why the mirroring function has not been applied up to now.
However, as an added step
before we send back the "mirrored video", we pass it
through our local pointer (PTR). This augmented videophone now
allows local users to point at items both in their local scene,
and in the remote scene, and both local and remote users can see
what they are pointing at (Fig. 3).
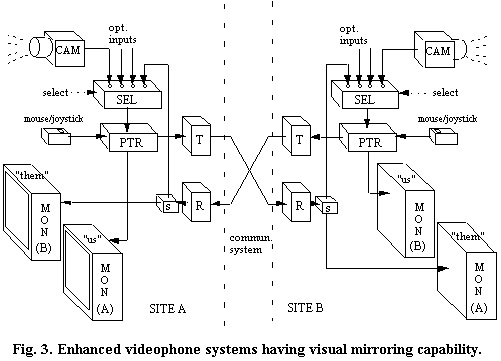
The mirror function is added
by splitting (S) the incoming signal from the remote site and
routing the added output into our video input source selector
(SEL). Digital implement-ations can be even simpler, and lower
in cost, in digital videophone systems already containing pointer
and selector functions.
Prototyping of Mirroring Systems
Readers who wish to explore these videophone concepts can easily build basic prototype systems for familiarization and evaluation. By using two video cameras, four monitors, two selectors, two pointers and some cabling, one can set up two sites similar to those in Fig. 3. Communication interfaces and remote links aren't required for basic user trials and application explorations; simply put the two sites in the same room, and block each from the other's view with a partition.
We have prototyped and explored videophone architectures, user interfaces and applications for several years, within a hybrid communications environment at the University of Michigan consisting of both analog broadband and switched digital links [3]. Most subsystems required for our prototypes were available as off-the-shelf consumer components, with the exception of video pointers and communication interfaces such as modulators and codecs. Several firms make analog video pointers as specialty products. We exploited a simple video sketch titler having a built-in pointer/overlay-mixer capability as a pointer in our prototypes.
Prototyping reveals some challenges. In analog broadband systems, image quality will suffer somewhat on rerouting through the local site, and on modulation and retransmission back to the remote site. In digital systems, after merger of the pointer into the decompressed image stream, the local recompression and remote decompression may also yield some losses in image quality.
But what are the alternatives?
Any separate path for control of a remote pointer leads to accuracy
difficulties if not carefully timed with, and located within,
the associated frames [4]. Then again, methods
which exploit unused scan line encodings may encounter problems
when transporting video across systems using different standards.
Mirroring has the advant-age of being low in cost and of carrying
the pointer's gesturing information unambiguously within the video
images themselves. (But, do avoid "mirroring" both sites
at the same time!)
Applications of Video Mirroring
In our prototyping experiences [3], we have observed that new users mainly exploited video mirroring to ask basic questions about things in remote locations. They often ask questions such as "Who is that?" or "What's that thing over there?" As users gain experience with mirroring, they gradually develop interaction skills they can apply to coaching and training people at remote sites.
The authors have often used mirroring to cope with equipment or cabling difficulties at remote locations while setting up and demonstrating our prototype systems. When a problem occurred, we asked remote users to aim a camera at their equipment, and then coached them on how to conduct tests and make corrections. With mirroring, even very low resolution video links can be used for remote site familiarization and orientation.
These experiences suggest that a general application for gesturing via mirroring is the enabling of remote assistance on practical, hands-on tasks. Such "remote coaching" could greatly enhance distance education, especially in hands-on fields such as medicine, nursing, engineering, design, and the training of technicians and equipment operators, etc.
The following scenario suggests the utility of mirroring: imagine that you are at NASA ground control, and a serious contingency occurs on a space shuttle. An astronaut interacts via video link to show engineers on the ground what is happening, hoping to get ideas as to what to do next. It would clearly be useful for those on the ground to be able to point at things in the shuttle to the astronaut.
However, for mirroring to be widely adopted to support such applications, we must create a user interface which is easy to explain and very easy to use. Only then can we help users learn to break out of the constraints of the existing paradigms of videophone usage.
One possible basic interface
for a two-window system is to automatically switch the outgoing
video to "mirrored video" when a user's pointer moves
onto the "incoming remote video" window. The occurrence
of mirroring could also be detected at the remote end and temporarily
block re-mirroring from that end.
Extension to Remote Visual Control
Now suppose that we want to control a simple mechanism at a remote site. Just as mirroring lets a person "point out what to do" to people at a remote site, mirroring and iconic gestures can also be used to "point out what to do" to a machine at a remote site. Importantly, this can be done using a simple videophone, without a separate computer-control link [5].
We first augment the videophone so that it can send any one of a set of graphic "control icons" in place of the pointer icon. Depending on the desired control function, the user selects a control icon and then positions it and "gestures" with it in the video mirrored to the remote site. The user interface can be imple-mented using a graphics pad to select and position icons (as in site A of Figure 4), or alternatively, it can exploit the cursor/pointer to select icons from an on-screen menu.
The remote site is augmented with a "visual interpreter" which scans the incoming video stream for particular graphic icons, as shown in site B of Fig. 4. Based on the type, location, gestural-movement and sequence of control icons seen in the mirrored video incoming from the user site, the interpreter selects and generates specific commands. These control commands are sent to the device controller of the selected mechanism at the remote site.
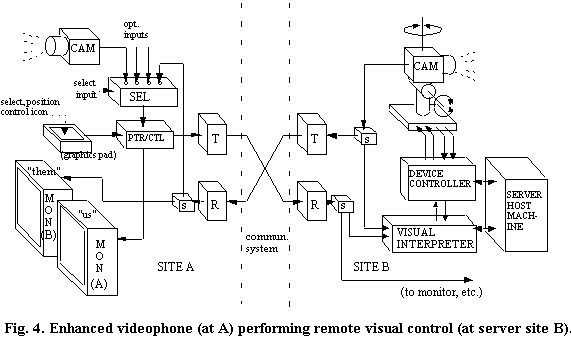
In the example shown in Figure 4, the remote mechanism under control is a simple pan-tilt-zoom camera. To effect control, users select and send a "select camera" icon in the mirrored video. This causes the remote visual interpreter to transition to the state "now controlling the pan-tilt-zoom camera". The type, location and gestural movements of subsequent control icons sent by the user are then interpreted to tell the camera controller "what to do next", such as "center on this point in the scene", "zoom in this much", etc.
Details of a basic visual interpreter are shown in Figure 5. The incoming remote video stream is digitized (if needed), and several video frames at a time are buffered in a memory. An "icon recognition processor" continually searches for matches between icons stored in an "icon pattern memory", and items seen in the incoming video memory.
The location and type of any icons found are then passed from the icon recognition processor to the "icon sequence interpreter" (Fig. 5). The icon sequence interpreter is a state machine which generates appropriate task commands for the device controller, as a function of the sequence, timings and locations of icons seen in the incoming video stream [5].
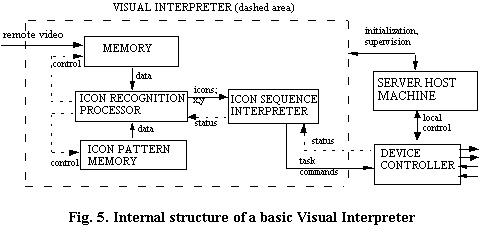
Note that the remote site could be a dedicated server having fixed
icon patterns and state sequencing codes. Alternatively, it could
be under control of a host computer so that icon patterns and
state sequencing codes are loadable (see Fig.
5). In that case, the host machine could also provide for
local control of the mechanism at the remote server site.
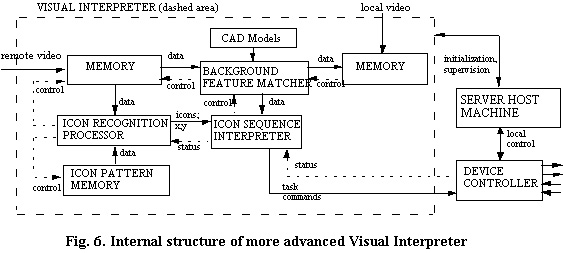
More advanced visual interpreters can use a "background feature matcher" to help identify, register and reference local objects, based on CAD models of the server site and video outgoing from that site (see Fig. 6). The CAD models can be updated by the server machine, as a function of server system activity.
The icon sequence interpreter interacts with the background feature matcher to register and interpret icons in incoming mirrored video with respect to objects in the local scene [5]. Such local-referencing capability at the remote site enables local closed-loop control on tasks initiated by icons, so as to do tasks such as "center on this object in the scene", etc.
Although this example shows visual control only of a pan-tilt-zoom camera, the general method can be extended to control of far more complex systems, such as robotic manipulators and mobile robots, by properly designing the machine selection, state switching and control icons for those mechanisms.
Furthermore, CAD-modeled, locally ident-ifiable objects in the scene, whether a VCR or a robot, can potentially be "selected" by pointing at them. They can then be "outlined" in the returned video to designate selection, and made accessible for further visual control.
Visual control has advantages over teleoper-ation methods which use a separate computer-control-link. Visual control can be simple and intuitive. Commands are explicit, observable and recordable from the video stream. Human-machine control activity can coexist with human-human visual communication over the same video links, and can be relayed across networks having multiple standards which interfere with non-visual control encodings.
Thus users of basic videophones
can be given the means to access and control complex, perhaps
expensive, remote equipment servers at many sites by using "iconic
visual control protocols" for those servers. All control
action can be generated without transfer of device-dependent parameters
between user sites and remote sites, and user sites need not contain
details of control methods or proprietary control software for
the remote mechanisms.
Prototyping Visual Control Systems
In order to explore and demonstrate remote visual control in practical applications, we built a prototype system to first control a high-performance pan-tilt robot camera "neck" [6]. We then extended the work to control the University’s M-Rover underwater robot [7].
M-Rover is an underwater robot having many degrees of freedom of motion control, camera control and manipulator control. Remote visual control allowed students and researchers to operate the underwater robot, located in the University's Naval Architecture tow-tank, from many University sites connected to our two-way broadband cable network [3] [7].
Our M-Rover visual control methods built on actual M-Rover field experiences in which people familiar with underwater search sites often "supervise" skilled M-Rover operators by looking over their shoulders and pointing in the video scene at what to do next. The difference is that the "supervisor" is remote from the control site, and the skilled operator at that site is replaced by a visual interpreter.
Although the M-Rover undersea mobile robot is quite complex, specific modes of operation are easily visualized. One mode involves driving M-Rover without controlling its camera or manipulator. In another mode, the camera is controlled while the robot is held in place. In a third mode, the robot is held in place and the manipulator is controlled, with the camera automatically tracking the end effector’s position. A mode is selected using the appropriate selection icon. Once a mode is selected, the user performs detailed control within the mode by pointing at particular image locations with appropriate control icons.
We used icons having distinct features, such as all white with black border, totally black with white border, or half white and half black. Such features are easily identified using basic image-processing algorithms. The visual interpreter performs convolutions on subsets of the image to find and identify icons. Once an icon is located, identified and in some cases tracked for a few frames, the resulting data determines an M-Rover control command.
Convolution operations, like other basic image analysis algorithms such as moments and thresholds, can be performed at video frame rate using standard hardware [8]. High-end devices, such as Datacube image processors, can be used in prototyping setups to guarantee processing at video frame rates. However, current image processing boards used as frame grabbers in personal computers also provide useful performance levels on simple icon sets. The speeds of the vision board, PC, and socket connection between the two determine the rate at which the system can search for icons.
Our early prototypes used 486 66-MHz computers, and enabled searching for icons at a rate of five frames per second using 7x7 byte icon masks convoluted with the image field [7]. Speed could be increased by searching for smaller icons or limiting the search area. By using a 300 MHz machine, the same operation could now be performed at a 30 Hz frame rate, even with a slightly larger icon mask (10x10).
Moving visual icons are suggestive of the hand gestures often used for non-verbal human communication. Many "gesture languages" are now in everyday use, such as that used by crane and excavation equipment operators [9].
Thus as prototyping progressed,
we explored systems in which iconic visual input was replaced
by using light pens to make simple oscillatory and line-motion
"hand gestures"[6]. Brightness-key
overlay enables pen motion to be made relative to a mirrored remote
scene. Higher-performance image processing is need-ed for tracking
and recognizing such dynamic gestures. But this capability could
further simplify client-system user-interfaces [6].
The dynamic control performance of such methods can also be made
quite high [6], in the absence of any significant
communication time delays.
Applications of Visual Control
Visual control exploits a low-cost local user interface to interact with remote mechanisms. The user (client) videophone simply needs a means for the user to select among graphic icons, and then point with those icons into the transmitted (possibly mirrored) video stream. The remote controlled mechanism (server) exploits a video interpreter to scan for, process and respond to incoming visual control icons.
Visual control shifts cost and complexity from user videophones (client) to the remote mechanism site (server). This shift can open up many new consumer-level videophone applications, especially in cases where large numbers of users may each occasionally wish to use specific remote equipment. Examples might be to access (1) complex video-based games that involve moving things in real remote environments, (2) training on how to operate real remote equipment, (3) control of sophisticated remote cameras for pan-tilt-zoom and motion on tracks, (4) control of, and viewing through, remote mobile robots, etc.
Visual control is analogous to using speech recognition to enable telephone users to interact with remote computer applications. The same idea applies; simple, low-cost devices provide access to specialized remote servers if those servers contain recognition and interpretation capabilities. (The analogy is even clearer if we use a hand gesture system rather than iconic gestures). As an added twist, designers of visual control applications should probably consider ways to jointly exploit visual and voice control methods.
Readers should be aware of one area of serious technical difficulty in applications of remote control, namely the problem of time delays in modern video communication links.
The cost of high-bandwidth links and the quest for image quality have led to development of complex encoding, compression and modul-ation techniques. However, these techniques come at a high cost in added communication time delays [10]. Of course very long-distance satellite links incur speed-of-light delays which can't be eliminated. But modern codecs and modems also insert large time delays even in short-distance links. Thus, when users tele-operate remote systems, they often encounter delays of 1/4 sec., 1/2 sec., or even 1 second in transport of video from the remote site [10].
Time delays on the order of 1 second seriously interfere with real-time teleoperation. While there are some known methods for coping with teleoperation time delays, they involve rather complex, forward-simulation-based systems [11] [12]. In cases where it is feasible, users might prefer coarser imagery delivered with shorter delays, when doing remote control.
Visual control can often take the form of mid-level supervisory control [11], in which the commands establish short time-frame goals for the manipulator to do, rather than trying to drive it continuously in real time. Time delay problems, while not fully removed, can be somewhat eased in such cases.
When facing really serious time delays, users wishing to control a remote machine may find it better to use basic video mirroring to coach a remote helper who then controls the machine for them. For example, studies have shown that, in the presence of time delays, the performance of remote surgery may be better when remotely coaching an assistant who controls a manipulator, than when remotely controlling the manipulator itself [13].
Thus we have come full circle,
and see an interdependency between applications of visual coaching
and visual control as a function of communication time delays.
Designers of videophone applications may therefore need to provide
easy ways to shift between visual coaching and control. Since
visual cues in the video stream can be interpreted by either humans
or machines, our visual coaching and control methods should readily
support such applications.
Conclusions
We have shown how to augment videophones with basic pointing, gesturing and mirroring functions. These functions are simple and potentially quite low in cost when added to mass-marketed videophone products, yet they promise to add considerable value by enhancing the interactivity of such systems.
We've also shown how to exploit videophones having pointing/mirroring functions to control remote mechanisms by using simple iconic gestures to "point out what to do next" to remote servers containing visual interpreters.
These control methods have the advantage of being visually explicit, observable and recordable, and are independent of the software and control system implementation details at the remote sites. Users of low cost videophones could potentially access and control equipment at any remote sites which make known their "iconic control protocols".
We believe that these visual
coaching and visual control functions fit into the category of
intuitive, easy-to-use, "every-citizen inter-faces"
(ECI) [14] being sought for application in
consumer-level video-computer-commun-ications. By adding a new
dimension of useful functionality at low added cost, these functions
can help stimulate wider, more rapid adoption of videophones in
practical, everyday use.
References
[1] S. K. Card, T. P. Moran and A. Newell, The Psychology of Human Computer Interaction, Lawrence Erlbaum Assoc., Hillsdale, N.J. 1983.
[2] L. Conway, System and Method for Teleinter-action, U.S. Patent 5,444,476, Aug. 22, 1995.
[3] L. Conway, "The UMTV Demonstration Project: Experiences in system architecture and educational applications of interactive hybrid communications", in World Conference on Eng-ineering Education, Minneapolis, MN, 1995.
[4] C-H. Wu and J. D. Irwin, Emerging Multimedia Computer Communication Technologies, Prentice Hall, Upper saddle River, N.J., 1998.
[5] L. Conway and C. J. Cohen, Apparatus and Method for Remote Control Using a Visual Information Stream, U. S. Patent 5,652,849, Jul. 29, 1997.
[6] C. J. Cohen, Dynamical System Representation, Generation and Recognition of Basic Oscillatory Motion Gestures, and Applications for the Control of Actuated Mechanisms, Ph. D. Thesis, University of Michigan, 1996.
[7] C. J. Cohen, "The M-Rover Remote Laboratory Project", Report to the Office of the Vice-President for Research, University of Michigan, Oct., 1995.
[8] P. I. Corke, Video-Rate Robot Visual Servoing", in Visual Servoing: Real-Time Control of Robots Based on Visual Sensory Feedback, K. Hashimoto, Ed., World Scientific Publ. Co., River Edge, N.J., 1992.
[9] Link-Belt Construction Equipment Co., Oper-ating Safety: Cranes and Excavators, 1987.
[10] S. Cheshire, "Latency and the Quest for Interactivity", White Paper for Synchronous Person-to-Person Interactive Computing En-vironments Meeting, San Francisco, Nov. 1996.
[11] T. B. Sheridan, Telerobotics, Automation and Human Supervisory Control, M.I.T. Press, Cambridge, MA, 1992
[12] L. Conway, R. A. Volz, M. W. Walker, "Teleautonomous Systems: Projecting and coordinating intelligent action at a distance", IEEE Transactions on Robotics and Automation, Vol. 6, No. 2, April 1990.
[13] M. P. Ottensmeyer, J. M. Thompson, T. B. Sheridan, "Cooperative Telesurgery: Effects of Time Delay on Tool Assignment Decision", in Proc. of the Human Factors and Ergonomics Soc. 40th Ann.ual Meeting, Philadelphia, PA, 1996.
[14]
Computer Science and Telecommunications Board, National Research
Council, More Than Skin Deep: Toward Every Citizen Interfaces
to the Nation's Information Infrastructure, National Academy
Press, 1997.
Biographies
Lynn Conway is Professor of EECS at the University of Michigan, Ann Arbor, MI. She earned her B.S. and M.S.E.E. at Columbia Univ. in 1962 and '63. She began her career as a Member of the Research Staff at IBM Research, Yorktown Heights, N.Y., where she made important contributions to high-performance computer architecture. Lynn is widely known for her pioneering work in VLSI design methodology as a Member of the Research Staff at the Xerox Palo Alto Research Center in the 70's. She has since made contributions to machine intelligence, collaboration technology and telerobotics at the Defense Advanced Research Projects Agency and later at the Univ. of Michigan. Her current interests are visual communications and visual control. Lynn has received many awards for her work, including the Electronics Award for Achievement, the Wetherill Medal of the Franklin Institute, the Pender Award of the Univ. of Pennsylvania, and an Honorary Doctorate from Trinity College. Lynn is a Fellow of the IEEE, and a member of the National Academy of Engineering.
Charles
Cohen
earned his B.S. at Drexel University in 1989, and his M.S. and
Ph.D. in Electrical Engineering at the University of Michigan
in 1992 and 1996. He is the Director of Engineering at Cybernet
Systems Corporation, located in Ann Arbor, Michigan. His current
projects include gesture recognition, eye-tracking, head-mounted
displays, and real-time object recognition and pose determination.
His major interests also include human-machine interfaces and
gestural control of devices. He is a member of IEEE.